"SECURITY"
Flowtriq: Instant DDoS Protection for Startups
"Are you hemorrhaging brand trust every time a botnet sneezes?"
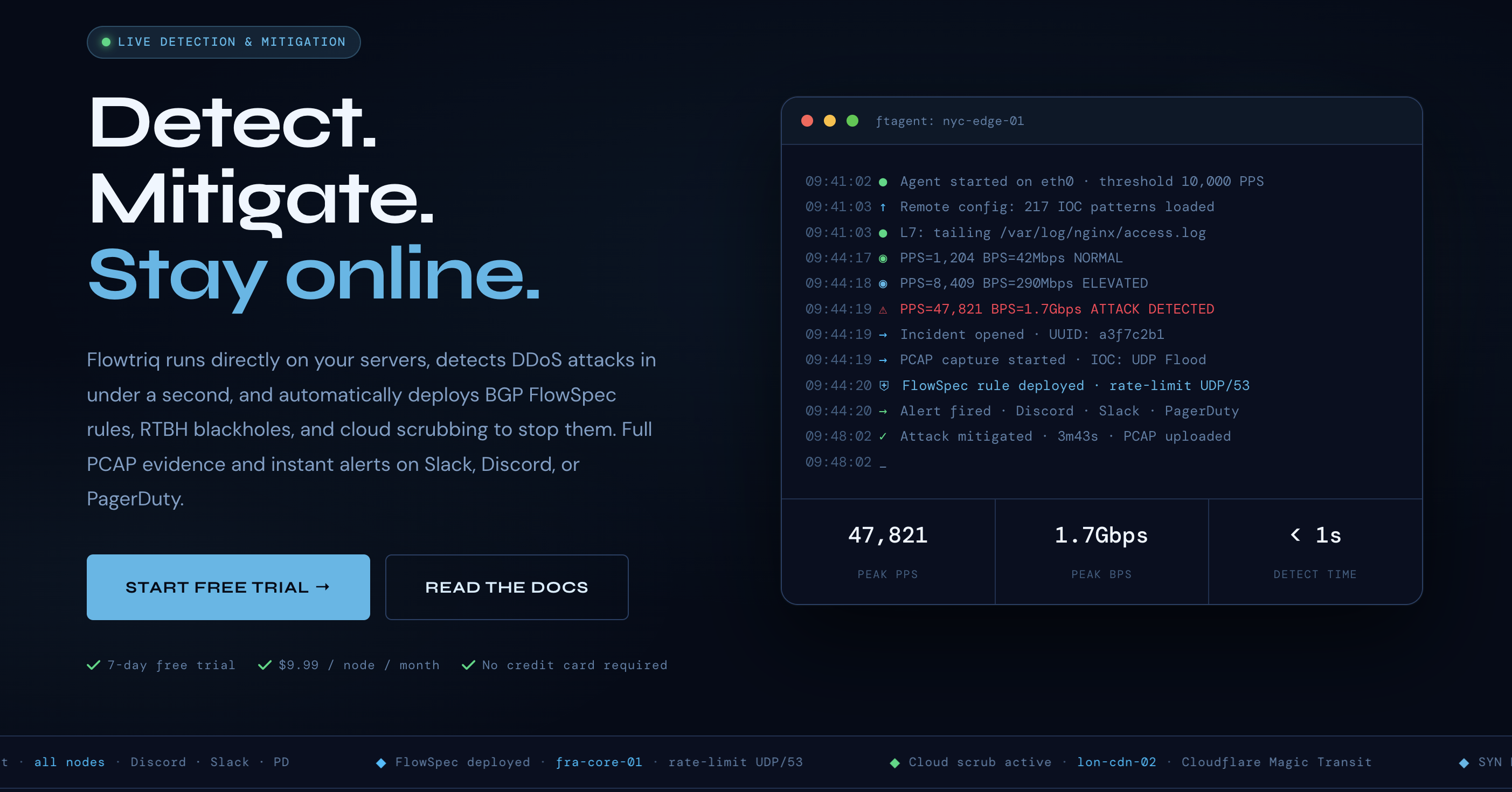
Flowtriq is a real-time, agent-based DDoS detection and auto-mitigation platform that installs on Linux servers in minutes and reacts in under a second—before users notice. For startup leaders, that translates to protected revenue, SLA integrity, and sleep. Bottom line: if uptime is a growth lever (it is), Flowtriq gives you enterprise-grade resilience at a flat, startup-friendly price without buying appliances or wrangling thresholds.
"The Business Case"
I’ve seen more startups lose customers to “intermittent weirdness” than to full-on outages. DDoS isn’t just downtime; it’s churn, SLA credits, support backlog, and paid acquisition dollars set on fire. Flowtriq’s sub-second detection and automated mitigation push your mean time to detect/respond toward zero, preserving session continuity and conversion rates when traffic spikes skew hostile. Because it learns baselines dynamically and triggers BGP FlowSpec, RTBH, or cloud scrubbing automatically, you’re not paying engineers to babysit dashboards or hand-tune thresholds.
The pricing model is the kicker: $9.99/node/month (or $7.99 annual) with no per-GB, per-alert, or egress surprises. That makes budgeting clean, especially versus scrubbing-only vendors who meter attack traffic. Revenue protection math is straightforward: a single avoided hour of degraded performance can pay for a year across dozens of nodes. Add the immutable audit logs and automatic full-packet captures per incident, and you’ve got compliance evidence and forensics without bolt-ons. Strategic edge: resilience as a default, not a fire drill.
"Key Strategic Benefits"
- →
Operational Efficiency:
- →Install via Python agent in under two minutes, then let it auto-learn and enforce in real time—no “set the right threshold” ritual. Playbooks chain mitigations so incidents execute like code, and alerts hit your existing channels (Slack, PagerDuty, Discord) in one second.
- →
Cost Impact:
- →Flat per-node pricing removes the “attack tax” many scrubbing providers sneak in. Fewer support tickets, fewer SLA credits, and less engineer context-switching during incidents equal real, trackable savings.
- →
Scalability:
- →Works per-node across fleets with multi-node management from a single dashboard. As you expand to more POPs or edge nodes, you add agents—not capex-heavy appliances—while escalation policies leverage upstream partners when volumetrics exceed local capacity.
- →
Risk Factors:
- →Linux-only agent means non-Linux endpoints need other coverage. You’ll want BGP FlowSpec/RTBH capability with your upstreams to maximize value, though Flowtriq also triggers third-party scrubbing. False-positive tolerance must be tuned via playbooks if you run highly bursty, event-driven workloads.
"Implementation Considerations"
Here’s how I’d roll it out without breaking sprint velocity. Week 1: pilot on 3–5 representative Linux nodes (API, game servers, or latency-sensitive SaaS edges). Install ftagent, connect to the cloud dashboard, and import alert channels. Confirm BGP FlowSpec/RTBH with your transit providers or set up integrations for cloud scrubbing (Cloudflare Magic Transit, OVH VAC, Hetzner). Week 2: define automated runbooks—start with rate-limiting and FlowSpec; escalate to blackhole or scrubbing based on PPS/impact. Enable automatic PCAP and verify audit log retention against your SOC 2/ISO policies.
Weeks 3–4: expand to priority services and edge nodes, then the rest of prod. Train on-call using a 30-minute tabletop with synthetic traffic to test alerting and mitigations. Resource-wise: one network/SRE owner, one security lead, and a product ops stakeholder is plenty. Change management is light; agents live next to your stack and don’t require architecture rework. From “First Look” to fleet-wide “Launch Alert,” you can be production-ready in under a month.
"Competitive Landscape"
Flowtriq’s angle is lightweight, on-host, sub-second detection with flat pricing—ideal for early and growth-stage teams. Scrubbing-first platforms like Cloudflare Magic Transit (https://www.cloudflare.com/magic-transit/), AWS Shield Advanced (https://aws.amazon.com/shield/advanced/), and Akamai Prolexic (https://www.akamai.com/products/prolexic) are powerful at absorbing volumetric attacks but often meter by traffic and can introduce routing latency. Hardware-centric solutions like Radware DefensePro (https://www.radware.com/products/defensepro/) and Corero SmartWall (https://www.corero.com/products/smartwall/) shine in datacenter cores but carry capex and longer deployment cycles.
Flowtriq complements these by detecting at the server edge, firing FlowSpec/RTBH instantly, and escalating to scrubbing only when needed—reducing cost and time-to-mitigation. If you already run a scrubbing backbone, Flowtriq becomes your per-node sensor and orchestration brain. If you don’t, it’s a pragmatic “First Look” that closes your biggest gap now and scales later.
"Recommendation"
My take: greenlight a 30-day evaluation across critical Linux nodes. Define success as reduction in time-to-detect/respond to <1s/30s, zero customer-facing incidents during load spikes, and clean audit/PCAP artifacts per event. If targets are met, commit to annual pricing at $7.99/node, formalize BGP/scrubbing escalation, and standardize playbooks. Add Flowtriq’s threat intel and attack profiles to your weekly ops review. This is a “Daily Drops” no-brainer that upgrades resilience without bloating headcount.
Bonus: their research chops (e.g., Mirai kill switch CVE-2024-45163) and free tooling signal a team you want in your corner. Fresh launches, dropped daily. Explore: https://flowtriq.com
"EXTERNAL LINK"
DON'T SLEEP ON THIS DROP